Evaluating LLMs - An Introductory Overview
The rise of large language models (LLMs) has transformed the AI landscape, enabling faster development of applications and lowering the barriers to creating functional prototypes. However, while it has never been easier to build an AI-powered MVP (Minimum Viable Product), the journey from MVP to production is fraught with challenges. At the heart of this transition lies a critical need for robust evaluation frameworks. These frameworks not only ensure that models meet task-specific requirements but also help mitigate risks, address safety concerns, and build trust among users and stakeholders.
This blog post explores key principles, technical approaches, and practical applications for evaluating LLMs.
The Importance of Evaluation
Evaluation is the compass that guides the journey from a functional prototype to a reliable production system. It enables developers and organizations to answer critical questions: Does the model perform well for its intended use case? Does it generalize effectively across diverse inputs? Can it handle edge cases? Is it safe and trustworthy?
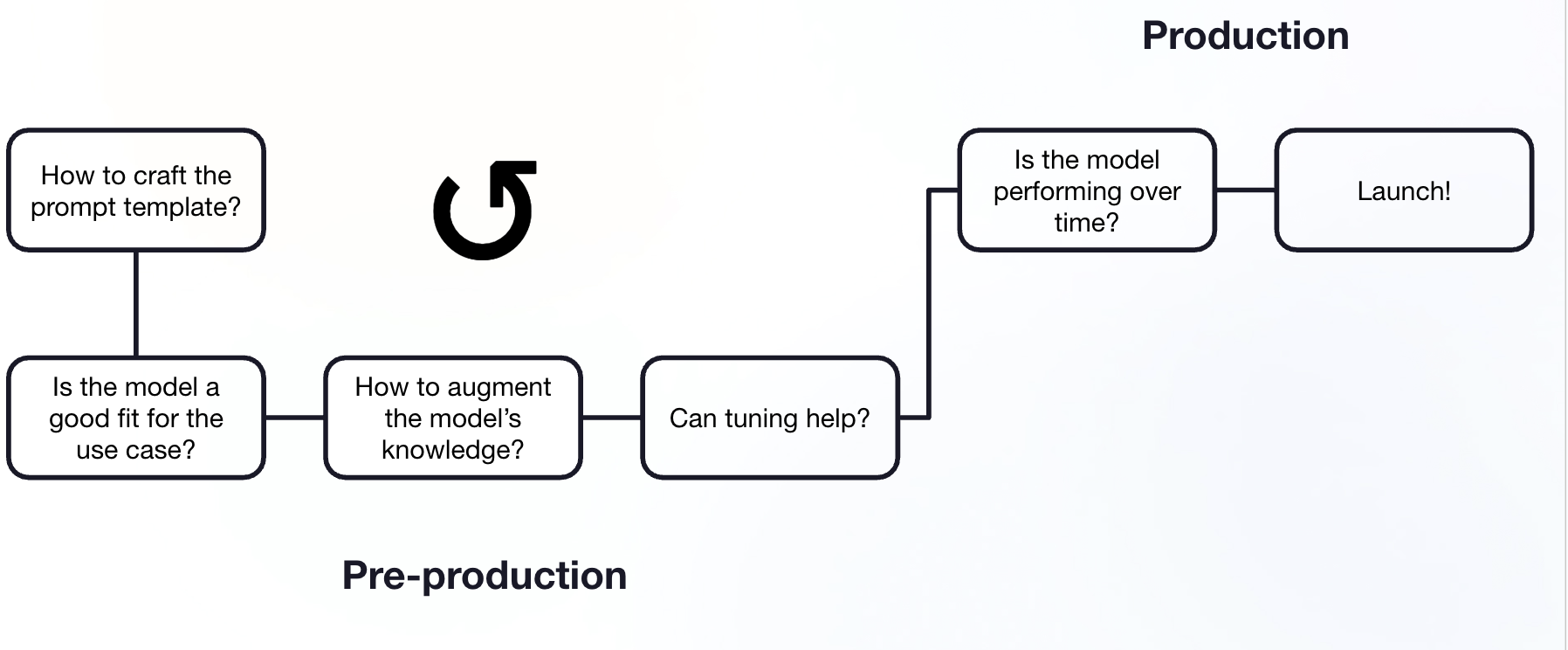
General model prototyping to production process where evaluation is key to making decisions.
In the era of LLMs, the evaluation process is more critical than ever. These models, while powerful, are not without limitations. They can hallucinate facts, generate biased or harmful outputs, leak sensitive information, and fail to generalize effectively in nuanced scenarios. A robust evaluation framework not only identifies these issues but also provides actionable insights for improvement.
Principles of LLM Evaluation
The evaluation of LLMs is guided by three overarching principles:
1. Task-Specific Evaluation
Generic benchmarks like leaderboards and public datasets are a common starting point for measuring model performance. However, they often fail to capture the nuances of specific applications. For instance, while summarization datasets may work for general text, they may not reflect the unique challenges of summarizing financial reports or legal documents. To address this, evaluation frameworks must be tailored to the specific task and domain, ensuring that the datasets and metrics align with real-world usage.
2. Context-Aware Testing
LLMs do not operate in isolation. In production, they are often integrated into complex systems involving retrieval mechanisms, tool usage, and agentic behaviors. Evaluating the model alone is insufficient; the entire application stack must be tested. This includes assessing intermediate outputs, understanding how the model interacts with other components, and ensuring that the end-to-end system delivers consistent, reliable results.
3. Defining “Good” Performance
Unlike predictive models, where accuracy or precision can serve as clear metrics, generative tasks often have multiple valid outputs. A single ground truth reference is rarely sufficient. Instead, evaluation must rely on criteria-based approaches, where outputs are assessed across dimensions like fluency, relevance, creativity, and domain-specific attributes. This iterative process often involves domain experts and evolves with the application.
Building Evaluation Frameworks
A robust evaluation framework begins with the creation of a representative dataset. This dataset should reflect the production environment as closely as possible to ensure meaningful results. Several methods can be employed:
- Manual Prompt Crafting: Developers and domain experts manually create input prompts that represent typical user queries and edge cases.
- Team Collaboration: Involving teams and domain experts can uncover corner cases and nuanced scenarios that may not be immediately apparent.
- Production Logs: Sampling real-world user data provides insights into how the model will be used in practice.
- Synthetic Data Generation: LLMs themselves can be used to generate synthetic data, enriching the dataset with examples that may be underrepresented or hard to create manually.
Once the dataset is established, the next step is to choose appropriate evaluation methods. These can be broadly categorized into three types:

Example architecture combining metrics
1. Computation-Based Metrics
Metrics such as BLEU, ROUGE, and embedding-based similarity scores are commonly used to evaluate text generation tasks. They measure how closely the model’s output aligns with a reference output. However, these metrics have limitations. They are often sensitive to the choice of reference and may fail to capture the semantic quality of the output, particularly for creative tasks.
2. Human Evaluation
Human judgment remains the gold standard for evaluating generative models. Annotators assess outputs for quality, relevance, and adherence to task-specific criteria. To ensure consistency and reliability, human evaluation typically follows a phased approach. Annotators are trained on a small sample of data to calibrate their judgments before scaling up to larger datasets. While effective, human evaluation is resource-intensive and time-consuming.
3. LLM-as-Judge (Moderator)
An emerging approach involves using LLMs themselves as evaluators. Moderators can assess outputs, compare responses from different models, and even provide rationales for their judgments. This approach is scalable and cost-effective, but it requires careful prompt engineering and calibration to ensure reliability. Techniques like self-consistency (multiple evaluations for consensus) and orchestration (using multiple models collaboratively) can improve the robustness of this method.
Evaluating Safety and Security
Safety and security are critical aspects of LLM evaluation, particularly as these models are deployed in sensitive domains like healthcare, finance, and education. Despite their capabilities, LLMs are vulnerable to a range of risks, including toxicity, bias, privacy leakage, and adversarial attacks.
Red Teaming
Red teaming involves stress-testing models to uncover vulnerabilities and edge cases. Automated red teaming algorithms are particularly effective at identifying risks that human evaluators might miss. For example, adversarial prompts can elicit harmful or biased outputs, revealing gaps in the model’s safety alignment. Similarly, privacy-focused red teaming can test whether models leak sensitive information, such as Social Security numbers or email addresses.
Multimodal and Code Generation Risks
The rise of multimodal models, which process both text and images, introduces new safety challenges. For instance, text-to-image models can be manipulated to generate inappropriate or harmful content. Code generation models, widely used in software development, are prone to generating buggy or insecure code. Advanced red teaming strategies are essential for identifying these risks and mitigating them before deployment.
Toward Certification and Standardization
While empirical evaluation provides valuable insights, it is not sufficient for ensuring safety and reliability. Certification frameworks offer a more rigorous approach, providing guarantees about a model’s performance and risk levels.
One promising direction is conformal certification, which uses statistical methods to provide risk bounds for generative tasks. For example, in next-token prediction, conformal methods can certify that the model’s predictions fall within an acceptable risk level under specific configurations. This approach not only enhances trust but also provides actionable guidance for model configuration and deployment.
Tools and Platforms for Evaluation
A number of tools and platforms have emerged to support LLM evaluation:
- Decoding Trust Platform: A comprehensive framework for evaluating trustworthiness and safety across multiple dimensions.
- LM Comparator: A tool for comparing model outputs, including rationales and performance across slices.
- LM Safety Leaderboard: An open-source leaderboard hosted on Hugging Face for benchmarking safety performance.
- ROUGE Score: A widely used metric for text summarization and generation tasks.
These tools enable developers to evaluate models more effectively, identify weaknesses, and iteratively improve performance.
Challenges and Future Directions
Evaluating LLMs is inherently complex, particularly for generative tasks where outputs are diverse and context-dependent. As models evolve, so do user expectations and production requirements, necessitating continuous evaluation. Additionally, the trade-offs between model capability and safety risks remain an ongoing challenge. Highly capable models, while powerful, are often more vulnerable to adversarial attacks due to their strong instruction-following abilities.
Standardization is another critical area. While tools and benchmarks provide a starting point, the field lacks standardized methods for certifying LLM safety. Developing such standards will require collaboration across academia, industry, and regulatory bodies.
Conclusion
The evaluation of LLMs is a multifaceted challenge that requires task-specific approaches, context-aware testing, and a clear definition of “good” performance. As the adoption of LLMs continues to grow, robust evaluation frameworks will play a pivotal role in ensuring their reliability, safety, and trustworthiness in production environments. By combining automated tools, human judgment, and emerging certification methods, we can build systems that not only perform well but also align with ethical and societal expectations.