Step 2: Create a Gold Standard Evaluation Set & Gather Data
This is an excerpt from the “Ready to Experiment with AI? A Guide for Getting Started”, which outlines a clear, four-step methodology to help you begin experimenting with AI more systematically and find useful applications. If you are a business leader, a life sciences professional, or an engineer who is just getting into the AI world - this guide is for you.
The 4-Step Methodology for AI Experimentation
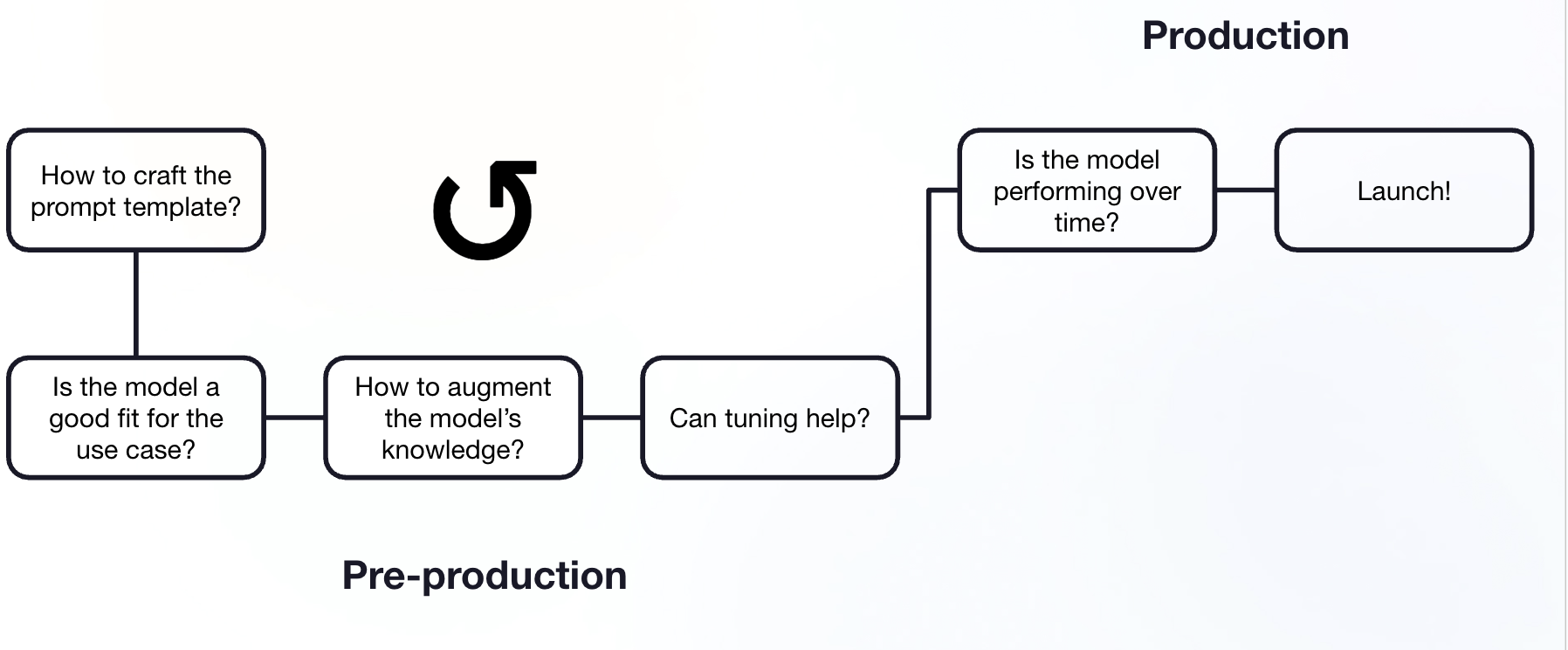
General model prototyping to production process where evaluation is key to making decisions.
Identify Outcomes & Tasks: Determine the goals you want to achieve and the specific tasks where AI might help.
Create a Gold Standard & Gather Data: Establish how you'll measure success and collect the necessary data.
Experiment & Pilot: Test different AI models on your chosen task.
Build & Deploy: Integrate the successful AI solution into workflows. You can complete steps 1-3 without engineering.
Let's dive into step 2.
Step 2: Create a Gold Standard Evaluation Set & Gather Data
Before serious experimentation, you need a reliable way to measure performance. This involves creating a "gold standard" evaluation set.
Let’s imagine that you are a wet-lab scientist who is looking to optimize experimental protocols. Here’s how to ensure your evaluation criteria and data are sufficient to measure the performance of the AI system you’re building out.
Expert-Created: This dataset should be built by someone who deeply understands the task and the workflow. In this scenario, you are the expert.
Sufficient Examples: Aim for around 100 diverse examples representing the task accurately.
In the case of the task “optimizing experimental protocols”, collect data examples from different experimental types, various experimental scales (such as small-scale pilot experiments to HTP screens), historical and published protocols, varied input data quality (noisy data, missing controls, incomplete metadata), and experimental constraints. Be sure to also include out of distribution cases, to reduce hallucinations. This will provide a range of situations for your program to learn from.
Structure: Each example provided should ideally include the input, the desired output (perhaps rated on a scale of 1-5, with 1 being the worst and 5 the best), and comments on the specific behavior being tested.
Held Back: This data is only for testing (inference) – models should never see it during training.
For initial, smaller-scale tests, you can track evaluations manually (e.g., in a table), noting the input, target output, actual model output, and other relevant factors. Remember to track all experiments systematically, as shown in the example below. At larger scales, this dataset is managed and benchmarked programmatically (example here), but to keep things accessible to anyone, we can keep it to a small number of examples.
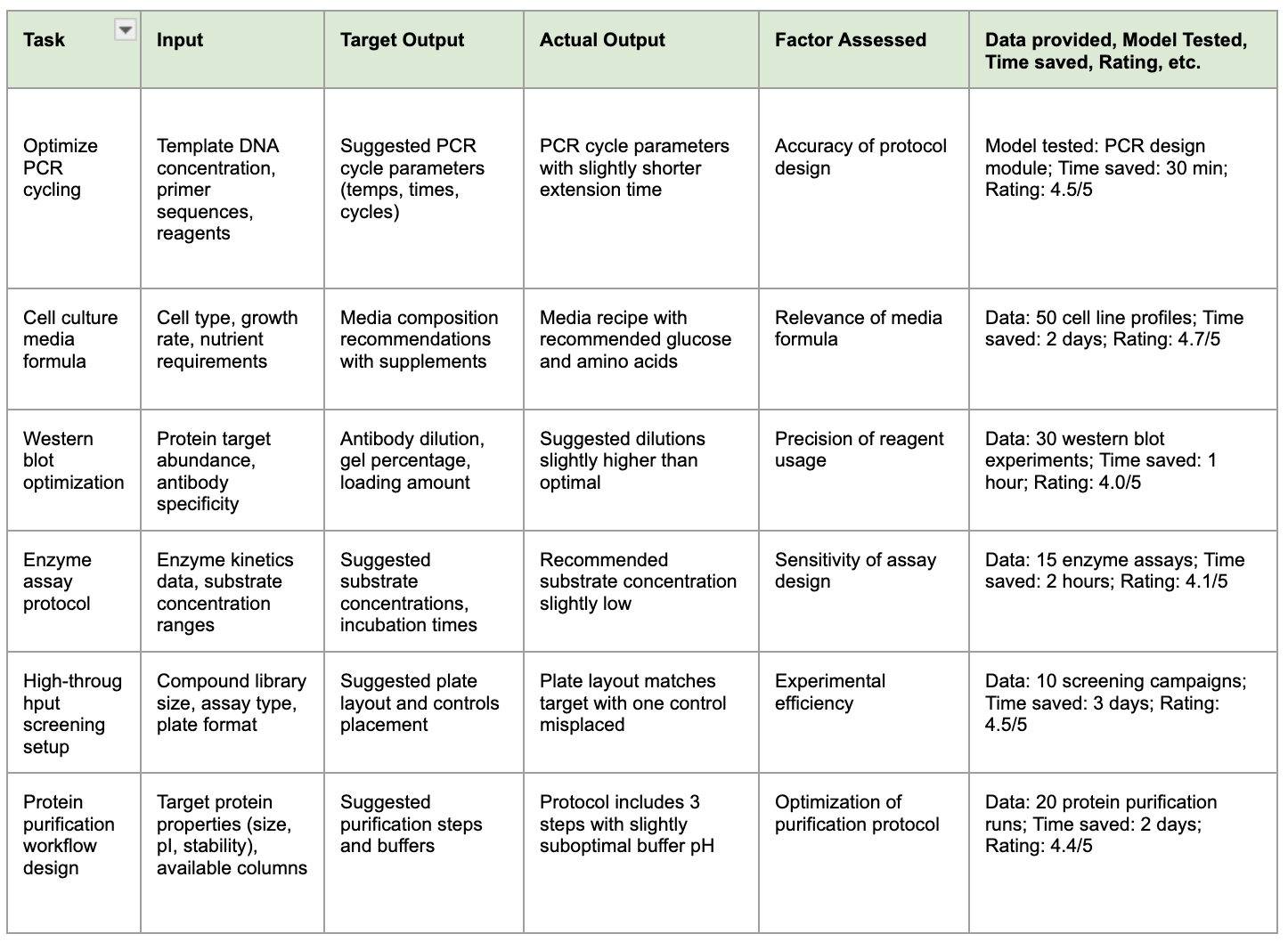
Diverse examples for a wet-lab scientist optimizing experimental protocols
Be sure to gather any data that could provide useful context for the AI, such as templates, style guides, or examples of similar completed tasks. The greater the range, the better your evaluation will be of the performance of your experiment.