The Innovations of DeepSeek
Background
The announcement of DeepSeek’s r-1 model took most of the world by surprise, though they have been active in top academic research conferences for several years now. Their reasoning model, in particular, created buzz around how cheap it was to develop. DeepSeek still hasn’t released the full cost of training r1, but it is charging people using its interface around one-thirtieth of what o1 costs to run. The firm has also created mini ‘distilled’ versions of r1 to allow researchers with limited computing power to play with the model (reference). This article focuses not on the media buzz, political agendas, or controversies, but the AI research innovations over the years that have led to this new reasoning model.
What They Delivered

Image: DeepSeek NeurIPS poster
The above is a technical poster of how their different research innovations fit together. We break it down below into a simpler image:
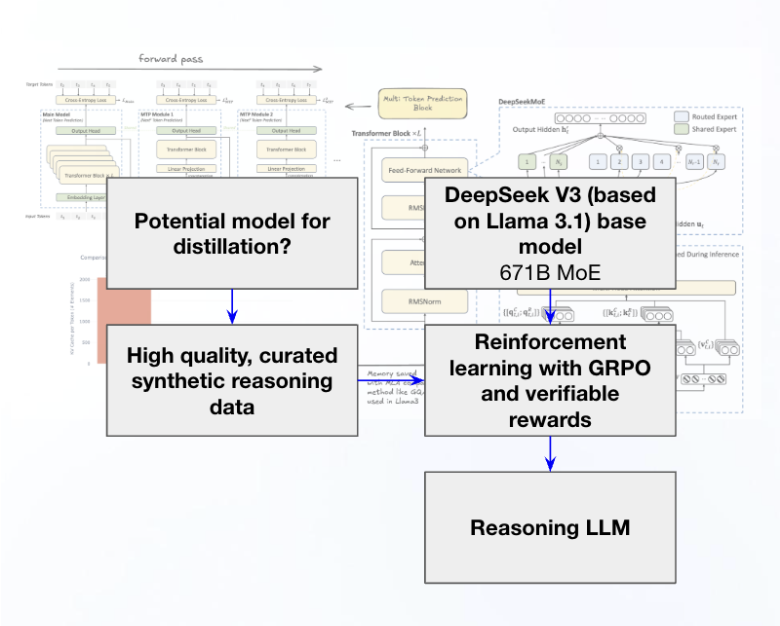
Image: KAMI Think Tank simplification of r1 workflow
Essentially, the reasoning model was developed by starting with the DeepSeek V3 671B parameter Mixture of Experts (MoE) model. This is the baseline pretrained model that was also only possible because Llama 3.1B is open-sourced by Meta. That is one key fact often skipped by media reports - reasoning models still require a multi-billion parameter baseline model to be fine-tuned off of. They do not exist independently.
This baseline large pretrained model is then fine-tuned with a reinforcement learning that uses a sparse GRPO with verifiable rewards, and fed into this is high-quality distilled synthetic reasoning data of about 600k samples.
The output of the RL process is r1, or the reasoning model. This model does require significantly less data than others, and is extremely cost effective (not necessarily only 5.5M total as that only accounts for the final training run and not the baseline multi-billion parameter model).
Research Innovations
We want to highlight specific AI research innovations that the DeepSeek Lab has contributed over the years to the community through publications, which have culminated in this achievement.
Highly curated coldstart dataset and efficient use of data (SLM) - There is some controversy as to how they distilled the synthetic dataset, but only requiring 600k samples of high-quality synthetic data is an achievement. On top of that, they published Selective Language Modeling (SLM) below, which is more efficient.
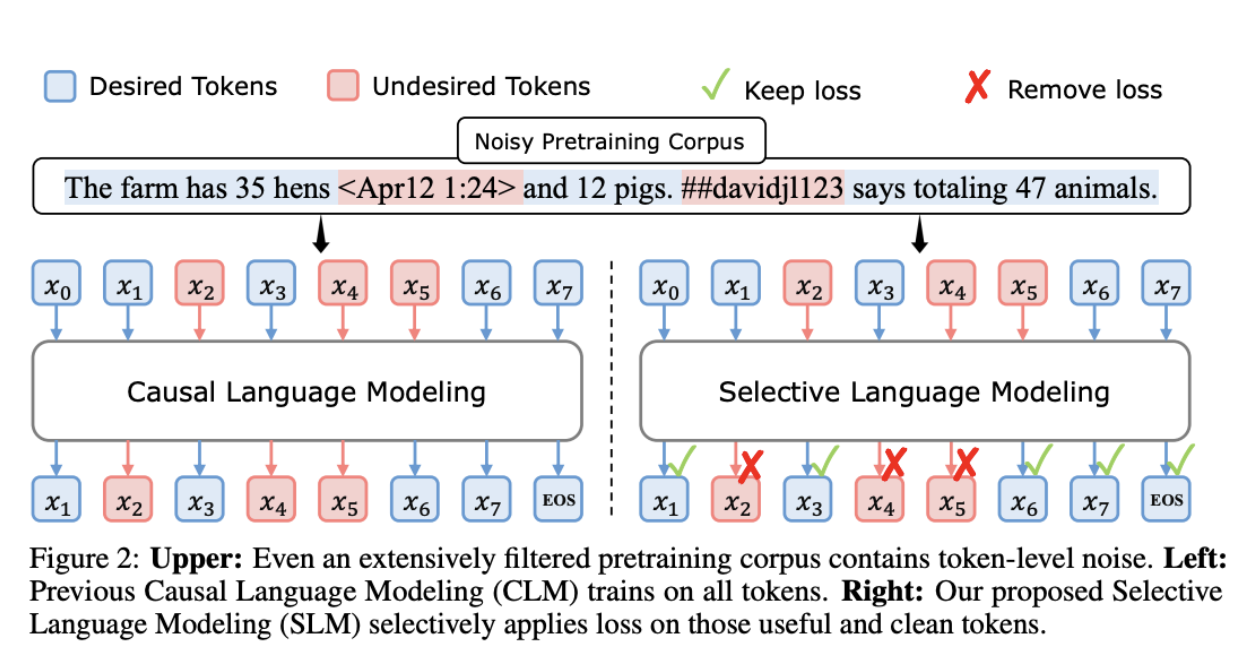
Image: SLM overview from DeepSeek paper.
Architectural changes (MTP, MLA, MoE, hardware) - MoE is much more efficient than other model architectures, especially at inference. They have contributed many other architectural innovations across multiple levels, down to the way bytes are passed at different levels of training, that advances the community’s understanding as well.
Skipping supervised training with GRPO reinforcement learning to improve reasoning in a highly cost-efficient way.

Image: Significant performance improvement on reasoning with top tier models with less data. From paper.
This is why tracking innovations from the AI research community are so important. As the time from research to production shortens, it is even more important to track research to get an understanding of what direction innovation is headed. Those tracking these labs and their publications will be ahead of the news cycle and jump ahead of the hype cycle.